
A few years ago, the concept of a High-Availability server was strictly accompanied by specialized hardware, complex node configurations and towering budgets. This naturally left the majority of businesses out, leading to a crippled internet sphere.
Today we have connected a large part of our activities to the internet. A great deal of our everyday routine is facilitated through it and as a result we cannot afford downtime as a part of our daily lives.
Naturally, numerous cloud hosting providers have realized this and strive to offer High-Availability cloud hosting on a budget.
- Can this be achieved?
- How is HA defined?
- How affordable can HA be?
- And what should you look out for when purchasing a High-Availability server?
Lazy? Quickly Check How to Determine If a Server Is High-Availability
- Tier 3+ or Tier 4 Data Center
- HA Hardware
- HA Storage
- HA Network
- HA Power Supply
- HA Cyber Security
- Tested 24/7 Support
- Thoroughly Check Provider SLA
Ready to Purchase a High-Availability Server?
What is High-Availability systems?
When a system is capable to remain available and functional almost continuously, especially when compared to other similar systems, then it is a highly available system.
But that’s a pretty vague explanation. Let’s dive into the specifics of High-Availability (HA);

What Does System Availability Mean?
All systems, servers included, need to be available to perform their tasks and produce meaningful, efficient outcomes.
System Availability (SA) is a metric that calculates the probability that a system is alive and well, and not down due to any type of failure or for maintenance.
Specifically, for a system to be available three factors need to be met:
No Maintenance: No scheduled maintenance or unexpected repairs should take place.
Functioning in Ideal Conditions: At a satisfying rate, to produce the expected outcomes.
Functioning When Needed: The system needs to be operational during scheduled production.
How Is System Availability Calculated for a Server?
It is pretty simple.
Server availability is the time during which the server was available (ie. its state satisfied the above three factors), divided by the sum of this uptime and the time the server was not available (ie. downtime).
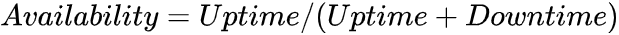
For example, let’s say your server supports your website, so it needs to be available continuously.
In a given month, the server was supposed to be running for all 730 hours.
However, 5 hours during the month were necessary to perform maintenance on the server.
Additionally, there were various failures here and there that resulted in 3 hours of downtime, during this month.
In total, downtime was 8 hours and uptime was 730-8 = 722 hours.
So, the server availability will be 722 / 730 = 0.989, or 98.9%
Why Is Server Availability Important?
Nowadays, we get more and more used to 24/7 running businesses and services, especially online. Being unavailable costs money, in the form of lost clients and potential income.
Actually, Gartner calculates the average cost of network downtime at an immense $300K per hour! Of course, for smaller companies or freelancers the cost will be much smaller. But it is still a cost, since during downtime there is no way to convert leads or create brand awareness.
This is why it is important to plan your server’s maintenance ahead, in a way that won’t affect numerous users for too long. Additionally, it seems more important that ever to invest in a High-Availability server.
What is a High-Availability Server?
The above information make it clear that a High-Availability server is a server deployed and configured in a way that allows it to operate for longer than an average server.
This allows the server to be used for business-critical activities within a company, or even for life-critical purposes in various industries.
For example, High-Availability becomes a necessity in healthcare monitoring, where an outage can be fatal, and stock-market platforms, where an outage can cause losses of millions of dollars.
Of course, High-Availability doesn’t need to save lives to be necessary. Any type of business that generates its revenue online should be based on a High-Availability architecture. Especially, if your website / app is the main or sole channel of revenue generation.
What makes a highly available server though? To answer this, we first need to know what is the average server availability.
What Is the Average Server Availability?
A study conducted by Hosting Facts around 2018, suggests that the average web hosting server availability is 99.59%, based on tested shared hosting plans from 32 web hosting providers.
Approximately, the average website faces 3 hours of downtime every month.
It is generally safe to say that any server availability above 99.99% can be considered high availability.
What Does High-Availability Architecture Mean?
For a server to be able to perform for so long it is evident that it needs to have a specific architecture and configuration.
A High-Availability architecture tackles three issues;
- Single points of failure are system components that cannot be bypassed or replaced in case they fail, and as a result the whole system is doomed to fail with them. A server based on High-Availability architecture is configured in a way that no SPOFs exist. This means that each server component has at least another (N+1) counterpart.
- A crossover point is a redundancy component / technique that takes on the task of delivering the work load from the failing component to the redundant component, for the duration of the failure. It is important to mention that the crossover point itself is a SPOF. A High-Availability server needs to also have a redundant crossover system.
- Real-time failure detection is necessary since for the duration of the failure the redundant component is a SPOF. There is no guarantee that an additional failure won’t happen, regardless of the possibility. As a result, it is important for the IT engineers to be able to work on replacing the failed component as soon as possible.
- Evidently, the bullet above proves that a 24/7 Support Service, although not a component per se, is a necessary part of a High-Availability architecture.
Which Components of a High-Availability Server Need to Be Redundant?
A High-Availability server has redundant components on the following levels:
- Data Center
- Storage
- Hardware
- Network
- Power
- Cyber Security
- Support Plan
This means that at all these levels there are no single points of failure. Let’s look into all of them.
A Physically Secure Data Center Location is Necessary
Choosing a suitable data center is of great importance.
The location of your server should be compatible with your business model.
For example, if your server is located on Sydney and your target audience is in the UK then they will experience latency that will affect their experience with your service. While your server might be functioning, it might hardly be operational for your clients.
Additionally, the quality of the data center will greatly affect your system’s availability. If you are aiming for a High-Availability system, then it is crucial to host it on a Tier 3+ or Tier 4 data center. Tier level is related to the overall availability of the data center.
For example, Equinix data centers around the world, on which MassiveGRID deploys High-Availability clusters, have an impressive uptime record of 99.9999% (six nines), which translates to 2 seconds of downtime monthly, or 31 seconds of downtime per year.
This availability level is the best possible base for a HA cloud hosting provider, such as MassiveGRID, to facilitate High-Availability clustering.
High-Availability Hardware
A High-Availability cluster consists of three nodes at minimum. Multiple nodes can be added live, to achieve efficient clustering with increased capacity.
Virtualization is then employed to deploy multiple virtual machines (VMs). It is possible for the VMs to be configured in very different ways, despite being on the same cluster or even node. This means that you can deploy a Windows server or a Linux server right away, with the same efficiency.
VMs are being spread on the available cluster nodes. Each VM uses the CPU and RAM resources of the cluster nodes it runs on.
In case of a hardware failure in any of the cluster’s nodes, the VMs that run on this node will automatically reboot on the other available nodes.
Automatic failover of the VMs takes place at the same state and configuration they were before the failure. This means that they will have the same storage, IP address and all the specifications and configurations they had before the failure.
High-Availability Storage
There are numerous ways to eliminate storage SPOFs.
One of the most reliable ways to achieve High-Availability storage is to combine triple replication with a self-healing configuration.
Automatic replication ensures that any block of data is stored in multiple disks. Of course, SSD disks are preferred for increased speed and reliability. Therefore, in case a disk, disk controller or a whole server fails, your data will be safe.
Note that triple replication is not a backup solution. Backup takes place periodically, at any given time you will be able to access the files that were backed up when the last backup took place, which could be a day, a week or a month ago. Triple replication distributes storage in real-time.
HA Storage should also employ mechanisms to always maintain the same redundancy level. Self-healing storage mechanisms guarantee exactly this.
In case a disk fails in a triple replicated storage configuration, 1 out of 3 copies of data is lost. The self-healing mechanism finds available space on any other disk of the cluster and copies data from the other 2 replicas, re-enabling triple replication of storage.
This process is done automatically and immediately after failures, ensuring maximum data reliability. During such events, the File System remains intact. All services that rely on the File System, like databases, are not affected at all.
High-Availability Network
Network connectivity should have redundant components too. Routers, internal and external switches and power distribution units (PDUs) should also be following an at least N+1 redundancy architecture.
It is also important to know where your cloud hosting provider receives connectivity services from. Tier-1 Internet Service Providers (ISPs) are directly connected to the internet backbone. By being directly connected to strategically interconnected computer networks and core routers of the Internet, you will experience faster connectivity. MassiveGRID, for example, receives connectivity exclusively from Tier-1 ISPs.
On a High-Availability server, traffic should be automatically re-routed in the event of a link failure. Providers should also guarantee internet connectivity maintenance through non-congested uplinks that are continuously upgraded, in terms of capacity, in order to offer the best possible connectivity.
High-Availability Power Supply
Leading-class data centers are typically offering at least N+1, up to 2N, redundancy configurations to all power supply components. This guarantees highly available power supply on all computing, storage and network components, which is essential for every HA system.
At least two independent high voltage (HV) feeds are used from the relevant distribution network operator (DNO), at least N+1 pairs of transformers and at least N+1 diesel generators are installed in each data center, capable of supporting at least twice or three times the total workload. In addition, monthly tests are performed on all generators (building load, as well as load bank tests).
Data centers’ Low Voltage (LV) infrastructure is at least in a N+1 and usually in a 2N configuration, having both A and B sides. Each side can fully support the load, although normal operating procedure is ideal for an active-active set-up with both sides running concurrently. At least N+1 and usually 2N UPS configurations are also in place on Tier-4 data centers, with various levels of battery autonomy.
The minimum autonomy is usually around 10 minutes. Based on the above, it is clear that it is highly unlikely for any service to have downtime, due to power supply reasons.
This is why it is very important to know where your HA server will be deployed. Don’t be afraid to make questions to your cloud hosting provider.
High-Availability Cyber Security
Modern cloud computing systems are increasingly complex. With this, security threats are becoming more sophisticated as well. Cyber Security protection against Distributed Denial of Service (DDoS) attacks, which are gradually growing in size, frequency and complexity, is a necessity for every High-Availability server.
It is essential to deploy a multi-layered security approach backed by extensive threat research to defend against a variety of attack types. HA Cloud Hosting providers, like MassiveGRID, should be capable to provide multiple layers of defense through:
- enhanced network routing,
- rate limiting and filtering
- advanced network-based detection and mitigation scrubbing center solutions.
Our mitigation approach is based on threat intelligence, which derives from visibility across our global infrastructure and data correlation. MassiveGRID can handle DDoS attacks and can enhance the protection threshold for clients with higher security expectations, up to 4.5 Tbps.
What Is a High-Availability Firewall?
A firewall is a network security device that monitors incoming and outgoing network traffic. It decides whether to allow or block specific traffic based on a defined set of security rules.
It is possible for firewall devices to fail too. To guarantee highly available security, it is a good idea to deploy at least two firewalls in the same cluster and synchronize them accordingly. This way single points of failure are eliminated and HA cyber security is possible.
Another technique is to deploy different types of firewalls in the same HA cluster. For example, it is possible for a Web Application Firewall (WAF) to be combined with a Stateful Packet Inspection (SPI) Firewall.
- WAF protects your web servers from infections, maintains secure kernels, and keeps you in the know with relevant information.
- SPI Firewall provides optimal intrusion detection and prevention. This SPI iptables firewall is straight-forward, easy and flexible to configure and secure with extra checks to ensure smooth operation.
The above configuration is utilized in the technology stack of MassiveGRID’s High-Availability cPanel Hosting solution.
High-Availability Support
Regardless of how sophisticated a High-Availability architecture is, all HA systems face failures every now and then. After all, 100% uptime is theoretical, since the mathematical function that calculates it is logarithmic, meaning that uptime can only tend to 100%, not reach it.
When failures happen it is crucial to have a technical support system in place, that will guarantee minimum downtime and thus minimum financial loss and frustration.
A basic yet crucial feature of a HA technical support system is 24/7 availability. This means that well-trained IT engineers need to be on stand-by constantly, regardless of time or day. 24/7 Support typically works with three 8-hour shifts every day.
It is important to trust the communication system of your support team. Different support teams work in different ways. In our experience, the best way to resolve technical problems or requests quickly and accurately is through a support ticket platform. Ticketing helps everyone keep the subject and actions organized. Additionally, all details are written down, so they are available whenever needed. This also helps to keep roles and responsibility defined.
Of course, additional support communication platforms are available;
- Bot Support: This type of server support is ideal when clients have simple, common requests regarding their services. Preconfigured answers with specific directions for a popular technical query can prove very helpful when a clients needs a quick insight on how to proceed.
- Chat Support: Chatting with the support team can be helpful when the client has simple, yet uncommon, technical requests. A support agent can provide personalized assistance instantly. However, it can be highly unproductive for a cloud hosting provider to resolve serious technical problems through chat. Accessibility is limited and various mistakes from either side, can complicate the problem further instead of resolving it.
- Telephone Support: For many of us, it feels great listening to someone telling you that it is all gonna be fine. Telephone support is the most personalized way to resolve technical issues. However, we can all see how it could be easily exploited and overused. This is why MassiveGRID offers 24/7 telephone support for clients with business-critical systems, who really need it. Of course, this type of support is more expensive, so it makes sense only if you really need it and can afford it.
To explore all the possible mediums, uses and requirements of IT support, feel free to check MassiveGRID’s support plans. These packages vary from a streamlined plan with essential support, for customers who wish to undertake any IT related task themselves, to SysAdmin Support plans, for businesses who wish to outsource SysAdmin tasks to MassiveGRID, up to Business Critical support plans with guaranteed response time and proactive engagement, in order to be certain that everything is being handled before any issues arise.
Keep Your Eyes on the Service Level Agreement (SLA)
Make sure to read the fine print when considering a High-Availability solution in the High-Availability server market.
It is very frequent for providers to claim High-Availability only for a specific level, usually on the network and power levels.
Of course, the server still has SPOFs on the hardware and storage levels, so it is not a server with a High-Availability architecture.
Providers that truly focus on High-Availability solutions will offer a universal 100% Uptime SLA.
For example, MassiveGRID clarifies that the Service Level Agreement includes potential downtime on all levels, even in case a failure occurs outside MassiveGRID’s infrastructure (eg. on the Data Center’s network infrastructure).
Additional Levels of High Availability
While HA best practices are thoroughly described above, it is possible that some additional features might be needed to complement it, especially when it comes to business-critical solutions. Load-balancing and regional failover, are two examples of such specialized needs. Let’s have a look at them:
What is the difference between High-Availability and load balancing?
Load balancing is a feature that can contribute to achieving high availability, however it is not necessarily a High-Availability component itself.
A load balancer is a device that acts as a reverse proxy. It practically distributes network or application traffic to multiple servers. As a result, the capacity of the primary server is not pushed to its limits. If this were to happen, users would face lags, delays and even failure to connect to the web page / application.
Thankfully, by utilizing a load balancer, the main web server can utilize a secondary server to break traffic load down to smaller, more easily manageable sections.
There are various models in regards to load balancing pricing, since a standby server that contributes to load balancing can be either dedicated at all times or utilized upon request of the load balancer.
So, depending on the use case, load balancing can be a crucial HA component. If your website’s or app’s traffic is pretty stable and you face no traffic spikes, then you don’t really need load balancing. If, on the other hand, traffic is dependent on seasonal or circumstantial factors, a load balancing solution can really help you achieve high availability.
A very user-friendly way to manage load balancing is through Jelastic’s Platform as a Service (PaaS) solution. In Jelastic’s PaaS offered on MassiveGRID’s HA infrastructure, it is possible to purchase fixed resources and less costly dynamic resources that will be only utilized, and you will only pay for them, if your website’s traffic demands it.
How Is Regional Failover Achieved?
Typical HA is not enough for large enterprises or organizations with global presence. It is possible that some failures might be caused by regional circumstances that no system in this region will be able to power through.
For example, if a big earthquake takes place in an area where a data center is located, there is not much to do to guarantee fault tolerance. Power supplies and optical fibers will break down, while vibrations will cause extended failures to hardware.
What happens then? There is still a way to achieve system availability regardless of regional circumstances.
MassiveGRID offers a Regional Failover solution where we deploy two servers, or clusters for larger clients, in two different regions. An active server, or cluster, is deployed in the location of interest, while another server, which can be either an active or passive server, is deployed in a different region that should not be affected by the same regional factors as the location of interest.
These backup servers are deployed in failover clusters which themselves are configured and deployed according to a HA architecture.
Failover clustering is a great approach not only for regional failover, but local failover as well. For example, numerous clients benefit from deploying private IT infrastructures in their own premises. If anything happens to their premises that causes their IT infrastructure to fail, we enable their systems to run through the nearest Tier-4 data center, achieving ultimate HA.
In the following image you can see a typical High-Availability architecture for our clients who enjoy our High-Availability Private IT Infrastructure service.
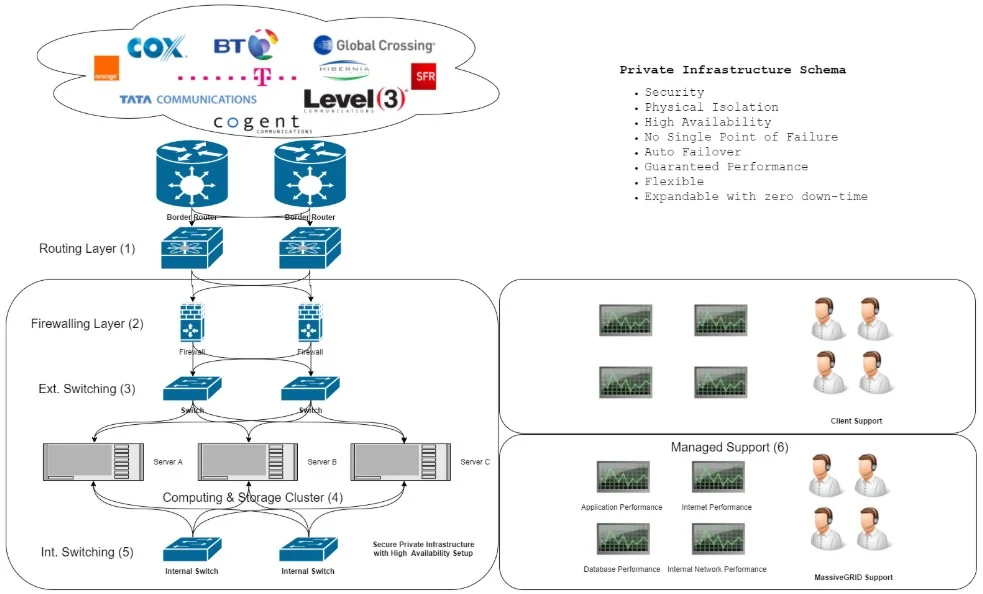
What Is the Role of a Passive Node in a High-Availability Server Cluster?
A High-Availability cluster typically consists of a secondary node and a primary node. The secondary cluster node can be either replicated through mirroring, and will thus be identical to the primary node, or it can be a downsized version of the primary cluster node.
In the event of a failure of the primary node, the secondary is taking over. If the secondary node is located in a different geographic region, then it can act as a disaster recovery configuration, against earthquakes or other “acts of God”. This is when regional failover has been achieved.
Conclusion
While there are ways to achieve High-Availability in an efficient way, it is still a highly demanding and complicated task.
It is very important that you study your HA provider in depth. Do not be afraid to ask tough questions, as this will save you money in the long run.
It would be smart to follow our High-Availability checklist to guarantee that your cloud hosting provider can indeed deliver maximum uptime and reliability for your service.