The No1 High Availability Cloud Provider
Cloud Services provided in infrastructures with built-in failovers and scalability, no single point of failure and the best 24×7 support rated 9.5/10. We’re proud to have been providing a consistent service for more than 20 years in 155 countries around our planet.


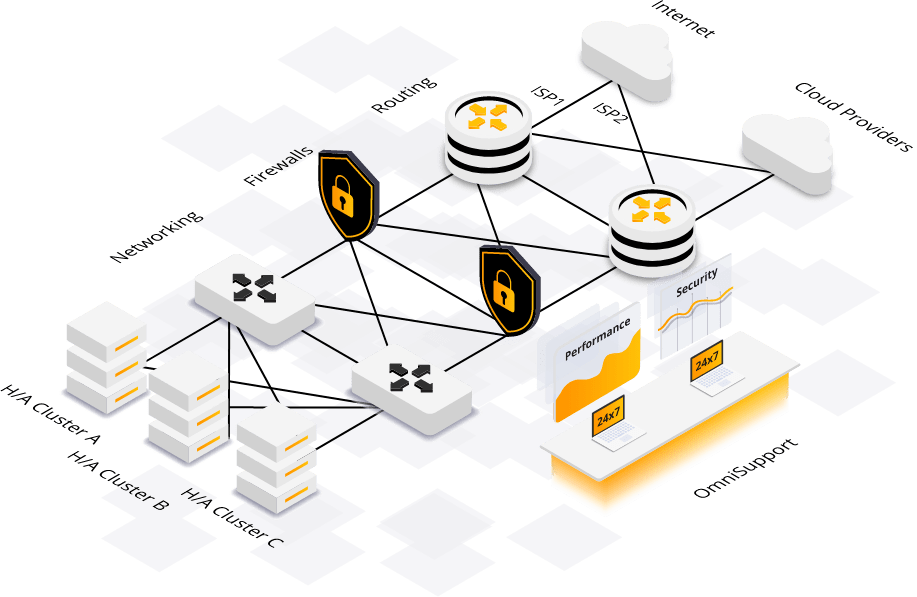
High Availability Clusters
All the services we provide run on our multi-master, high-availability clusters. These clusters provide the underlying and "out of the box" high availability for all your services on MassiveGRID
Redundant Networking
Every part of our Networking is redundant with automatic failovers built in. That doesn't only apply to the infrastructure but also to the end-user services making 100% of our infrastructure run without a single point of failure.
Security
Your services running on MassiveGRID are protected from our security layers that include Firewalls, DDoS Protection, Web Application Firewalls, Intrusion Detection and Prevention Systems, all running with redundancies and with no single points of failure.
Redundant Routing
Redundant Routers connected with multiple Tier-1 Internet Backbone providers and other Cloud Providers providing the lowest world-wide latency, the best reliability and ample bandwidth over uncongested links.
24x7 Support
Dedicated in-house 24x7 support teams ensure uninterrupted assistance and resolution for any issues or inquiries you may encounter with our cloud services, guaranteeing peace of mind around the clock.
")
")








Solutions

for Hosting
Fast, Reliable and Secure Hosting in our H/A Clusters.
Developers / Agencies
Friendly to develop PaaS and robust Private Clouds for Production.
Enterprises
Top Security, Reliability and Performance for Enterprises on Cloud or on Premises.

Government
Secure, High Performance, Ultra reliable GovCloud Solutions.

Partners / Resellers
Utilize MassiveGRID premium cloud services for your clients.