
Cloud Outages Happen All Around Us in 2020 While Cloud Providers Fail to Adopt a High-Availability Model.
What Can You Do to Secure Your Company?
Mass Cloud Providers Still Fail to Deliver Reliable Cloud Experiences
- Honda Halts Production after Suspected Cyber Attack
- IBM Cloud Goes Down with Prolonged Outage
- Google Cloud Platform Faces More Than Enough Outages in 2020
- AWS Goes Down in Sydney
- Xbox Live Goes Down After Microsoft Outage
Honda Halts Production After Suspected Cyber Attack
Automotive manufacturer Honda is experiencing a company-wide network outage that is suspected to have been caused by a ransomware attack, according to international media reports.
British news organization The Telegraph today reported the automaker’s servers have been infected with EKANS malware, which targets industrial control systems (ICS) that interface with heavy equipment in factories and plants. The EKANS ransomware shuts down specific ICS processes indefinitely, encrypts data and demands payment in exchange for decryption.
Connectivity issues within the Honda network began Sunday and have not yet been resolved. A company spokesperson confirmed that the situation has impacted operations but did not say whether the issues are due to a cyber attack.
“On Sunday, June 7, Honda experienced a disruption in its computer network that has caused a loss of connectivity, thus impacting our business operations,” a Honda spokesperson said. “We have canceled some production today and are currently assessing the situation.”
Messages seeking additional details on the extent of the disruption have been left with representatives of Honda’s corporate affairs department.
Ransomware attacks have escalated dramatically in recent years and have largely targeted businesses, often disrupting factories and basic infrastructure. In 2019, more than 205,000 organizations submitted files that had been hacked in a ransomware attack — a 41% increase from the prior year, according to data from security firm Emsisoft.
The FBI sees roughly 330 cyber attacks per week in the Dayton region alone. Last year, Rexarc International Inc. beefed up its investment in cybersecurity after falling victim to an attack where hackers stole more than $100,000 from the West Alexandria-based welding manufacturing firm.
“The world is changing,” Travis Greenwood, CEO of Dayton’s largest networking technology firm told DBJ in 2019. “The need to protect company assets has never been higher.”
Honda has experienced disruption due to ransomware attacks before. In 2017, the automaker’s computer network was infected by the WannaCry worm, causing a temporarily production shutdown at one of its plants in Japan.
Honda is the largest manufacturer in the Dayton region, according to DBJ research. The company maintains more than 2.6 million square feet of space at its engine plant in Shelby County and employs 3,200 workers in Miami Valley.

IBM Cloud Goes Down With
Prolonged Outage
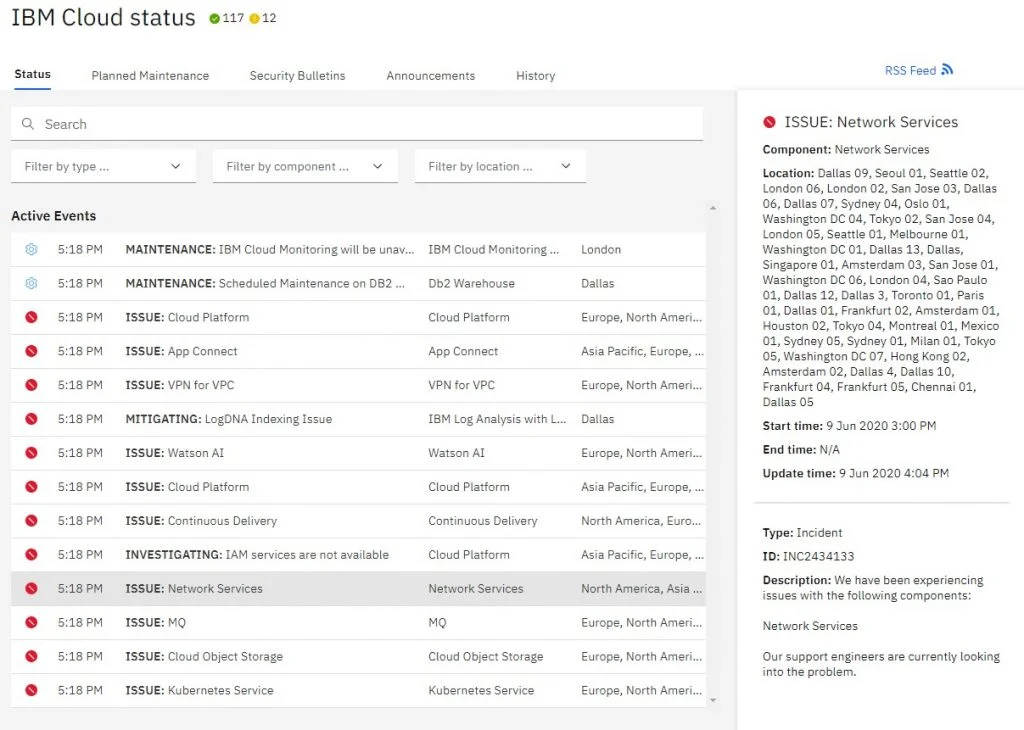
The IBM Cloud is currently suffering a major outage, and with that, multiple services that are hosted on the platform are also down, including everybody’s favorite tech news aggregator, Techmeme.
It looks like the problems started around 2:30pm PT and spread from there. Best we can tell, this is a worldwide problem and involves a networking issue, but IBM’s own status page isn’t actually loading anymore and returns an internal server error, so we don’t quite know the extent of the outage or what triggered it. IBM Cloud’s Twitter account has also remained silent, though we found a status page for IBM Aspera hosted on a third-party server, which seems to confirm that this is likely a worldwide networking issue.
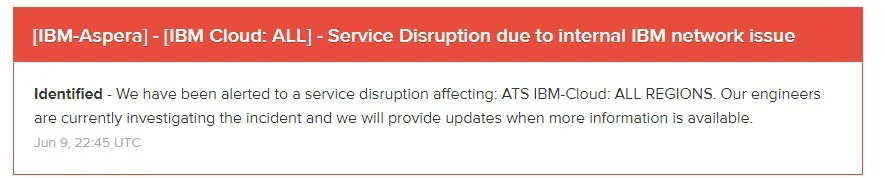
BM Cloud, which published a paper about ensuring zero downtime in April, also suffered a minor outage in its Dallas data center in March.
We’ve reached out to IBM’s PR team and will update this post once we get more information.
Update #1 (5:06pm PT): we are seeing some reports that IBM Cloud is slowly coming back online, but the company’s status page also now seems to be functioning again and still shows that the cloud outage continues for the time being.
Update #2 (5:25pm PT): IBM keeps adding additional information to its status page, though networking issues seem to be at the core of this issue.
Google Cloud Platform Faces More Than Enough Outages in 2020
Google Cloud Platform had more than its fair share of cloud outages for 2020, especially during the COVID-19 pandemic.
Google App Engine
GAE20002 Began 26 March 2020, lasting 1 hour 10 minutes
GAE20001 Began 17 January 2020, lasting 44 minutes
Google Compute Engine
GCE20003 Began 26 March 2020, lasting 11 hours 7 minutes
GCE20002 Began 26 March 2020, lasting 54 minutes
GCE20001 Began 28 January 2020, lasting 28 hours 7 minutes
Google Cloud Storage
GCNET20004 Began 27 March 2020, lasting 49 minutes
CNET20003 Began 26 March 2020, lasting 1 hour 5 minutes
AWS Goes Down in Sydney
AWS suffered a lengthy and wide-ranging outage on cloud services operating out of its Sydney region.
Users began to report issues with services at 11.15am AEDT and it took until 5.30pm for the problems to be resolved.
The issues affect services including EC2, elastic load balancing (ELB), relational database service (RDS), AppStream 2.0, ElastiCache, WorkSpaces and Lambda.
“@awscloud EC2 instances are not visible on AWS platform. Error fetching instance data across all accounts in Sydney region,” one user said.
“Sydney AWS EC2 console seems down and deployments are failing saying ‘internal simple workflow issues’,” another user tweeted.
On EC2, AWS said the issue “mainly affects EC2 RunInstances and VPC [Virtual Private Cloud] related API requests.”
“A data store used by a subsystem responsible for the configuration of Virtual Private Cloud (VPC) networks is currently offline and the engineering team are working to restore it,” the cloud provider said.
“While the investigation into the issue was started immediately, it took us longer to understand the full extent of the issue and determine a path to recovery.
“We determined that the data store needed to be restored to a point before the issue began.
“In order to do this restore, we needed to disable writes.”
The cloud provider apologised for the extended outage and the impact it had on a range of large and small Australian organisations.
“We apologise for any inconvenience this event may have caused as we know how critical our services are to our customers,” it said.
“We are never satisfied with operational performance of our services that is anything less than perfect, and will do everything we can to learn from this event and drive improvement across our services.”
Xbox Live Goes Down After Microsoft Outage
Microsoft’s Xbox Live service experienced issues today, marking the fourth time in recent weeks. Xbox One users were reporting problems earlier today with signing into Xbox Live, accessing friends, and joining parties. The issues started at around 3:15PM ET, and also affected some multiplayer games. The outage was not isolated to Xbox Live; Microsoft says it was an issue persisting throughout its platforms, including Microsoft 365.
“We are aware that some users may be experiencing issues when attempting to sign in on Xbox One & Windows 10,” Microsoft explained in a status update put out on Twitter “Our teams are aware & working on a fix. Please follow here & on our status page for updates.”
Microsoft said it’s was investigating issues affecting “multiple Microsoft 365 services,” too, suggesting the outage was broader in scope and went further than just Xbox Live. Microsoft has experienced multiple outages with Xbox Live recently, and this is the fourth outage in recent weeks. Xbox Live was down for two hours last month, affecting party chat and online multiplayer.
Around 4:50PM ET, Microsoft put out an update on its Xbox Support Twitter account saying it had resolved sign-in issues for Xbox Live and Windows 10. “We’ve resolved an issue that a subset of customers may have experienced trying to sign-in to some services,” the company later said in statement given to The Verge. According to the Xbox Live status page, however, the platform is still apparently seeing issues around account creation, management, and recovery, as well as persistent problems joining players in multiplayer games.
Update May 22nd, 6:27PM ET: Added a statement from Microsoft saying the company had resolved the sign-in issues and most services should now be operating normally. The headline has also been updated to reflect this information.
Conclusion
A High-Availability (HA) model cannot be approached in the context of a low-cost, one-size-fits-all service.
HA architecture is a business model by itself which is based in specialized data centers, hardware infrastructure and configurations.
Outages might not occur every day, but when they do they can heavily impact your organization’s revenue and brand image.
Study our HA model or start exploring our HA services and elevate your organization today.